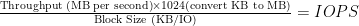vSphere Storage APIs for Storage Awareness (VASA) are one of several VMware vSphere Storage APIs. VASA, new in vSphere 5.0, provides vCenter with a way of interrogating storage array LUNs and associated datastores to gain visibility into the underlying hardware and configuration of the storage layer. Storage capabilities, such as RAID level, thin or thick LUN provisioning, replication state, caching mechanisms, and auto-tiering are presented through VASA to vCenter (a unidirectional read operation by vCenter against the array). With VASA, vCenter can identify which datastores possess certain capabilities. By associating a VM – or specific virtual disks within a VM – to storage profiles, we can begin to take advantage of VMware’s Profile Driven Storage capabilities. With VASA helping to guide VM placement, IT can deliver a higher quality of service to match SLA’s.
A few examples of how using VASA can help IT guarantee SLAs are:
- A user-defined storage profile defined for ‘High Speed Sequential Write’ could be associated with a VMDK used for database logging. This same profile would be assigned to VMFS datastores based on RAID10, with ample write cache.
- VM’s running critical applications could be associated with a storage profile for ‘Synchronous Replication’. Datastores protected by a SAN-based replication package (such as EMC SRDF or EMC RecoverPoint) would be assigned this profile to guarantee replication of VM’s on the datastore. VMware SRM would then be used to guarantee crash and application consistency, and automated failover/back capabilities.
- Test/Dev VM’s could be associated with a storage profile for lower tiered disk without a flash based caching mechanism (i.e. EMC FAST Cache) to keep low priority machines from consuming expensive disk and cache.
- A cloud provider configures multiple tiers of storage in a gold/silver/bronze fashion and assigns appropriate storage profiles to the datastores. Customers choose which tier they want (based on cost vs. performance) and have VM’s automatically provisioned on the correct storage tier. This can be done in vCenter or in vCloud Director!

VASA-enabled profile driven storage can be combined with vSphere Storage DRS for automated capacity and performance (IOPS) load balancing of like-datastores. Greater degrees of automation decrease risk while improving SLA’s. Taken one step further, VMware’s forthcoming vVols technology will basically create a bidirectional VASA capability, where a VM can tell the underlying storage what performance, features, and capabilities it requires and the storage array will automatically create a VMDK on itself to match the demands from the VM.
EMC VNX fully supports the current version of VASA in vSphere 5.1. To give you an idea of what data can be seen through VASA, here are the storage capabilities exposed [Read more…] about Configuring VMware VASA for EMC VNX

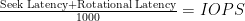
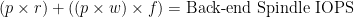
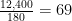
 (LaTeX is the language I used to make the cool math equations – if the forumlas don’t look right drop a comment so I can fix them. WordPress keeps eating the latex syntax…). Hopefully your SAN admin already knows this, so go ahead and give her your front-end IOPS count and read:write ratio and you’ll get some LUN’s presented. But you, the VMware admin, might be responsible for server hardware, including buying the interconnect card (HBA, iSCSI NIC). How do IOPS inform your selection? This is where the alternate formula for calculating IOPS comes in. Here’s the forumla:
(LaTeX is the language I used to make the cool math equations – if the forumlas don’t look right drop a comment so I can fix them. WordPress keeps eating the latex syntax…). Hopefully your SAN admin already knows this, so go ahead and give her your front-end IOPS count and read:write ratio and you’ll get some LUN’s presented. But you, the VMware admin, might be responsible for server hardware, including buying the interconnect card (HBA, iSCSI NIC). How do IOPS inform your selection? This is where the alternate formula for calculating IOPS comes in. Here’s the forumla: