 It’s been a long time since I published an article in my Storage Basics series – the series has been some of the top content on my site to date. I sat for a beta version of the VMware Certified Advanced Professional – Desktop Design (VCAP-DTD) test today and was reminded by the test of a post I had in waiting about an alternate way to calculate IOPS (hint hint – memorize these formulas). I have several more articles sitting in draft form, but a new job, crazy kids, home improvement projects, and a wife with chronic cerebral spinal fluid (CSF) leaks (it sounds bad – and it is – but look on the bright side: not many guys can get away with saying that their wife’s brain leaks!) all take time. But enough excuses and back to storage….
It’s been a long time since I published an article in my Storage Basics series – the series has been some of the top content on my site to date. I sat for a beta version of the VMware Certified Advanced Professional – Desktop Design (VCAP-DTD) test today and was reminded by the test of a post I had in waiting about an alternate way to calculate IOPS (hint hint – memorize these formulas). I have several more articles sitting in draft form, but a new job, crazy kids, home improvement projects, and a wife with chronic cerebral spinal fluid (CSF) leaks (it sounds bad – and it is – but look on the bright side: not many guys can get away with saying that their wife’s brain leaks!) all take time. But enough excuses and back to storage….
I wrote in Storage Basics – Part II: IOPS on how to calculate theoretical IOPS for a given disk type and speed, and then followed it up in Storage Basics – Part III: RAID with some information on how different RAID configurations impact IOPS. I.E. More disks equals more IOPS, but with a write penalty assigned for different RAID types. I then moved into a discussion of interconnects in Storage Basics – Part IV: Interface, but didn’t do a good job there of tying the interconnect speed to performance and IOPS. Finally, in Storage Basics – Part VI: Storage Workload Characterization, I hinted briefly on how I/O request size can impact storage performance. Let’s dig into this topic a little deeper!
The Original IOPS Forumula
Calculating IOPS at the disk/RAID level is fun and all (and I suggest you brush up on it if you are sitting for the VCAP exams), but does not paint a full picture of the storage subsystem. The basic formula to get a single disk IOPS (I covered this in Part II) looks like this:
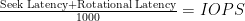
(The LaTeX formulas keep getting messed up – sorry if they don’t look right. Let me know and I’ll fix them, again).
For simplicity sake, let’s just assume that this formula yields 180 IOPS for a standard 15k RPM SAS disk (the industry standard number of IOPS for this speed and type of disk)
The formula for RAID IOS is in Part III – here’s a sample for RAID5, where:
p = IOPS required, f = write IO penalty factor, r = % Read, w = % Write
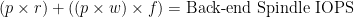
Let’s put it to use: let’s say I have a workload that I’ve measured as needing 4000 IOPS from the OS/application perspective, of which 70% are write (not unusual in VMware View Linked Clones): here’s how you figure out how many disks you need from an IOPS perspective for those linked clones:
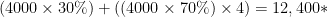
*12,400 Back-end IOPS needed on my spindles in a RAID5 array
Then, convert the number of back-end IOPS needed to a number of disks needed given our RAID5 assuming the 15k SAS disk:
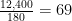
That is, I need 69 disks (rounded up) required on the back-end to meet our 4000 front-end IOPS, ignoreing things like best practices when putting a bunch of disks in a RAID group/storage pool (4+1 RAID5 sets) and hotspares (1 in 30 for SAS)
A quick run at the math suggests that you should probably not be using RAID5 for a write-heavy workload (run the math yourself with a write penalty of 2 for RAID0+1 to see how many fewer disks you would need). Also, this particular example leaves out any calculation for cache impact, including EMC FAST Cache or the View Storage Accelerator (CBRC). If you have those technologies in the mix, then a very rough rule of thumb would be to size your back-end IOPS based on your front-end IOPS calculation (4000 in the example above, instead of 12,400) – I say very rough because this really depends on your cache size and cache hit ratio, and the rule pertains a bit more to read-heavy workloads than write heavy. If you have CBRC in the mix, you *might* be able to greatly reduce and maybe eliminate the Read IOPS from the equation. But before you go taking my word as gospel, test, test, and test some more using your particular workloads.
The Alternative IOPS Formula
But this is all back-end spindle stuff and me having fun with 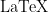
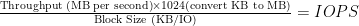
Warning: I had initially written this based on simple Gb to mB conversion – totally ignoring encoding, baud line rates, overhead, duplex settings, etc. This skewed the number of IOPS that the formula yielded upwards of what is really possible. Thanks to Stephen Foskett and Phil Jaenke for keeping me honest on these numbers and some fun Twitter back-and-forth. Real throughput numbers for different devices can be found here: https://en.wikipedia.org/wiki/List_of_device_bandwidths#Storage. While I’m using ‘real’ line rates now, keep in mind that this is all still theoretical. Your real world experience will differ, perhaps even differ drastically, depending on your unique environment.
Thanks again Stephen Foskett for this formula for converting FC to rates:
For 1, 2, 4 and 8Gb FC with 8b/10b encoding:
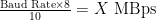
Then convert Mb to MB:

Solved for 8Gb FC with a rate of 8.5MBaud (8.5GHz) we get:
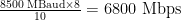
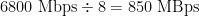
For 16Gb FC, encoding is changed to 64b/66b encoding. Otherwise the math is similar: 1700MBps
I’ve updated the numbers below to reflect the real-world numbers above as of 1/2/2013.
So let’s say you have a sequential write throughput of 850MBps (i.e. 8Gb FC), and block sizes of 64KB (default block size for Windows XP/2003). The theoretical IOPS in this situation is as follows:
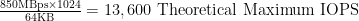
Now, let’s swap that 8Gb FC HBA for a 10Gb Ethernet storage protocol (iSCSI, NFS, or FCoE – we’re just talking theory here, so pick your poison):
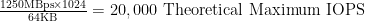
Let’s say you are rocking 16Gb FC HBA’s with the latest version of vSphere – 5.1 (5.1 introduced full support for 16Gb FC HBA’s:
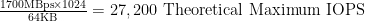
Bottom line here: more bandwidth = more throughput = more IOPS. But, your back-end spindles must be able to support this level of IO. 16Gb FC ain’t pixie dust that makes latency on spinning disks go away.
Now, keep vSphere 5.1 and your 16Gb FC HBA’s but switch to Windows 7 View Desktops or Windows Server 2008 R2, which both try to use 1MB block sizes (on aggregated write I/O). In reality, you probably won’t see a whole lot of 1MB block sizes in your VMware workloads as Windows memory pages are still 4k in size, and thus files are loaded into RAM in 4k blocks, and ESXi may randomize and split up IO further – more in Jim Moyle’s document on Windows 7 IOPS for VDI: A Deep Dive. You can capture and view your block sizes, and plot out the data in ESXi using vScsiStats. But for the sake of science, let’s work the numbers:
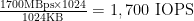
Whoa – what just happened there? Bigger block sizes gave us lower IOPS potential? Yep, and that’s a good thing. We’re moving the same or more data through the pipe, but doing it with a lower IOPS requirement from our back-end spindles. And at the same time, we’re realizing greater CPU efficiency on our hosts (10-15% reduction in CPU on your ESXi hosts when you switch from 8Gb FC to 16Gb FC according to VMware’s Storage I/O Performance on vSphere 5.1 over 16 Gigabit Fibre Channel whitepaper).
Now, let’s flip the equation around (digging deep to remember my 7th grade algebra here) and assume our 4000 IOPS requirement from our earlier example. Also assume that we’re dealing with a 4KB I/O size typical of many Windows workloads. Let’s calculate how much storage bandwidth you need to satisfy the requirement:


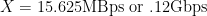
In this example, you’ll be using roughly 12% of your 1Gbps iSCSI or NFS. A pair of 1Gbps NIC’s for storage traffic and you are set (as long as your storage admin carves up enough spindles and/or cache to support that 4000 IOPS).
So there you have it. A couple ways to calculate IOPS requirements to figure out both back-end spindles for a given workload, as well as interconnect speeds for the workload. Put both numbers together and you’ll be well on your way to correctly sizing your next storage implementation. Questions, comments, or class clown comments? Drop a line below!
Extra credit:
- Play with the numbers to see how different block sizes impact decisions around storage protocols/interconnects. I.E. – SQL with 8KB IO, backup applications with 256KB IO, etc.
- Think about Storage Alignment – how does a misaligned partition cause this math to get funky? Hint: 2 blocks being returned for each IO when misaligned.
- For a little more reading on IO size and IOPS, I recommend the following:
- Improve VDI Performance with IO Length Trending – read down through the comments (Chad Sakac has a good one here: https://myvirtualcloud.net/?p=988&cpage=1#comment-3620).
- Large I/O Block Size Operations Show High Latency on Windows 2008 – good info on ESXi breaking down large guest disk IO into smaller block sizes.
- VMware View Storage Considerations: Covers a bunch of storage related items, including block size and the IOPS formula I introduced here.
Keep Reading:
- Storage Basics – Part I: An Introduction
- Storage Basics – Part II: IOPS
- Storage Basics – Part III: RAID
- Storage Basics – Part IV: Interface
- Storage Basics – Part V: Controllers, Cache and Coalescing
- Storage Basics – Part VI: Storage Workload Characterization
- Storage Basics – Part VII: Storage Alignment
- Storage Basics – Part VIII: The Difference in Consumer vs. Enterprise Class Disks and Storage Arrays; or ‘Why is the SAN you are proposing so darn expensive?’
- Storage Basics – Part IX: Alternate IOPS Formula
If you want to see all of the articles in my Storage Basics series, visit this link: https://vmtoday.com/category/storage/storage-basics/.
Just wanted to clarify that ESXi doesn’t randomize or split any IO’s. The Hypervisor will pass any IO it receives directly through to the driver and underlying storage without any modifications, ordering or splitting. It is completely pass-through. So whatever the hypervisor receives from the Guest OS is what the underlying storage will receive. The only case where there might be a change is where the hypervisor reduces the storage queue slots available to a particular VM or VMs when enforcing SLA’s as part of Storage IO Control. But even in this case the IO’s themselves are not changed, ordered, randomized or split. Just the number of available queue slots reduced.
Great feedback Michael – thanks. There’s a lot of conflicting info out there on if ESXi changes IO size, and how it all interacts with NTFS cluster allocation size, VMFS block size, stripe size, array block size, 512 vs. 4k formatted drives. All different topics, but somehow end up all jumbled together with no clear info.
Some of the results from your formulas may be inaccurate. The formula for the 10GB Ethernet should result in 20,448, not 20,4480. The formula for the 16GB Fiber should result in 32,768, not 20,4480.
Thanks for catching these – I found the same errors and tried to edit before publishing but wordpress crapped out (using Varnish cache server on my host and it is eating posts). Editing again now! Great to know that I’ve got folks who are doing a detailed reading of my work!
As noted on Twitter, your maximum theoretical bandwidths are a little off…
Should be:
800 or 850 MB/s for 8 Gb FC (I use 800 MB/s) for 12,800 IOPS
1250 MB/s for 10 GbE for 20,000 IOPS (close enough!)
1600 MB/s for 16 Gb FC (even though they switched to 64b/66b they use a slower baud rate so don’t get the same throughput benefit as GbE) for 25,500 IOPS
Of course this is all theoretical. In the real world, a switched FC network usually stands up better than Ethernet when hammered. But you really can get massive IOPS out of either –
10k 64 KB IOPS is not impossible! But it’s not likely either, especially considering the limited range of storage devices that could do it!
Great article! 🙂 I blogged about this kind of IOPS calculation some years ago (03/2008) and from another point of view (MB/s=IOPSxIO Size) and only in german language (https://www.blazilla.de/index.php?/archives/270-MBs-vs.-IOPS.html)
Nice stuff there! I usually calculate with the industry standard numbers, but this approach is refreshing 🙂