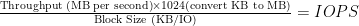Several months ago I was called into a new customer to diagnose some odd behavior in their VMware View environment. The organization was struggling with constant disconnects and generally poor performance on their View desktops. When users weren’t being randomly disconnected from their desktops, the users experienced lag when dragging windows between multiple monitors, ‘choppy’ graphics/video, and slow application launching. The problems occurred with local and remote users (both WAN and LAN could be involved). The customer had done some troubleshooting, worked with VMware Support and the their local account team but the problems persisted. Without a resolution and increasingly frustrated users, the local VMware account team recommended that ClearPath be engaged to perform a rapid, yet comprehensive health check and analytic troubleshooting service on the View environment, as well as the related storage, network, and vSphere components. The customer asked for a 24 hour turn-around on identifying and fixing the problems in the environment, so I had my work cut out for me.
Several months ago I was called into a new customer to diagnose some odd behavior in their VMware View environment. The organization was struggling with constant disconnects and generally poor performance on their View desktops. When users weren’t being randomly disconnected from their desktops, the users experienced lag when dragging windows between multiple monitors, ‘choppy’ graphics/video, and slow application launching. The problems occurred with local and remote users (both WAN and LAN could be involved). The customer had done some troubleshooting, worked with VMware Support and the their local account team but the problems persisted. Without a resolution and increasingly frustrated users, the local VMware account team recommended that ClearPath be engaged to perform a rapid, yet comprehensive health check and analytic troubleshooting service on the View environment, as well as the related storage, network, and vSphere components. The customer asked for a 24 hour turn-around on identifying and fixing the problems in the environment, so I had my work cut out for me.
The customer had done a lot of things right – starting with choosing VMware View and pushing a virtual desktop solution to a variety of use cases across the organization. Their vSphere environment was well designed, network was highly redundant and the storage backing View had recently been upgraded to an all-flash array to try to resolve the slowness observed by VDI users. The customer had also implemented VMware vCenter Operations (vCOps) for View and Xangati’s VDI Dashboard to help identify the root cause of the problems. The only major thing that either of the tools showed was major PCoIP packet loss (upwards of 30% much of the time, with spikes much higher) and high PCoIP latency (even on the LAN with sub-1ms latency). Armed with this basic information and admin level access to vSphere and View I rolled up my sleeves and got to work.
Network Analysis
Knowing that high packet loss has been an ongoing condition, I started my investigation with the network. Teradici, the makers of the PC-over-IP Protocol (PCOIP), recommends that packet loss within a single PCoIP protocol session should target less than 0.1%. Higher levels of packet loss can exhibit the behavior experienced by the users. I started with interviewing the network team to understand the topology and configuration. The network team insisted that their network had never lost a packet, and indeed the network was sound. Buffers were not being overflowed and networking gear did not show packet loss at all. Packets did not seem to be re-ordered upstream, a condition that can cause poor PCoIP performance. I also verified that remote users were direct connecting to the View Security Servers without bring wrapped in a TCP/SSL VPN as this can re-order and re-transmit packets when the UDP-based PCoIP stream is wrapped in TCP. Teradici has a knowledge base article titled ‘What Can Cause Packet Loss in a PCoIP Deployment’. I reviewed that, but everything in the article was already eliminated during my time with the network team. Finally, I walked through the PC-over-IP® Protocol Virtual Desktop Network Design Checklist with the team and found a few areas for improvement. With ample bandwidth, no latency, no packet loss, no re-ordering, and almost everything in the checklist already done, I felt fairly confident that the problem was not LAN/WAN related.
So now I have PCoIP packet loss according to View Connection Servers and View desktops, but it isn’t on the network; Now that is interesting. Time to shake up my train of thought on this problem – think outside the box. What if the problem wasn’t really PCoIP packet loss, packet loss was merely a symptom? That’s like treating the sneeze while ignoring the flu. Time to dig deeper into the other components of the environment.
 Storage Analysis
Storage Analysis

Next up: storage. As I mentioned, the customer had recently implemented an all-flash array. I found a few issues with how the array, fabric, and hosts were configured. First, the array was not connected to the hosts with full redundancy as pictured to the right. This setup did not provide multiple paths to the storage array. Having multiple paths not only provides redundancy and resiliency, but can improve performance by taking advantage of additional storage buffers, array cache on both controllers, and greater concurrency of IO activity if using a third-party multipathing plugin like PowerPath/VE.
I looked at the array and found that it was performing well – it was satisfying all of the IOPS being requested by the workload. Cache hits were high, no errors,  dropped frames, etc. The storage fabric was 8Gb fiber channel, and was not being taxed as far as throughput was concerned. Flash is well suited for the high random IO patterns you see in virtual desktops, and great for View Linked Clones where the shared replica disk is hit very hard from an IO perspective.
dropped frames, etc. The storage fabric was 8Gb fiber channel, and was not being taxed as far as throughput was concerned. Flash is well suited for the high random IO patterns you see in virtual desktops, and great for View Linked Clones where the shared replica disk is hit very hard from an IO perspective.
The flash array did not support VAAI (a firmware update was released the same week to enable VAAI, but it wasn’t on when I started my analysis), so I expected some View Composer operations to be a bit slow, and some SCSI reservation issues if there were too many VMs in a VMFS datastore. The customer had less than 64 Linked Clones per datastore, so I wasn’t terribly concerned.
I encouraged the customer to patch in all ports on the array to the storage fabric, as well as both HBAs on their hosts, for greater redundancy and better scalability as pictured to the left, but otherwise the storage array and FC switches had a clean bill of health.
View Infrastructure Analysis
Now onto the View management components – vCenter, Composer, Connection Servers and Security Servers. I reviewed the topology to make sure servers were placed on the network in the correct way as shown below:

The topology was fine, so I looked at the individual servers. Composer and vCenter were configured correctly, and could not be directly implicated in any performance problems on View desktops.
The Connection Servers and Security Servers were not configured with the recommended amount of vRAM and vCPU. While there was no sign of pressure on the servers by my analysis (Windows Perfmon, analyzed by my View PAL tool), I wanted to eliminate any potential problems now (and in the future). VMware recommends 4 or more CPUs and 10GB or more memory on Connection Servers for deployments of more than 50 desktops. I was dealing with several hundred desktops here, so more resources were in order. The customer was able to add resources without downtime. Cross another thing off the list.
vSphere Health Check
Next up I turned my focus to the vSphere environment. I used the vSphere Health Analyzer to quickly access the environment. vSphere Health Analyzer is a tool available to VMware Partners like Clearpath for health check services (a View specific Desktop Health Analyzer, as well as a new version of View Planner – a load testing tool for sizing View environments has since been made available). The tool uncovered about 30 potential issues with vSphere. Out of those, only two could have a significant impact on desktop performance: 1.) NTP was not configured properly on the ESXi hosts, and 2.) many View Desktops were configured to use VMware Tools to get their time from the host. This meant that the desktops were getting invalid time from the hosts. To make matters worse, the Windows Time service was running and trying to get time from the Active Directory hierarchy. This could lead to time flapping as VMware Tools and the Windows Time service fight to set the time. With time flapping occurring, I could see in the Windows event logs that some scripts, GPO processing and other startup tasks were long-running or not completing. This explained the slow booting the IT group saw, but not significant on-going performance issues. I passed on all my findings to the customer and moved on to analyze the desktops themselves.
Horizon View Desktop Analysis
To analyze the desktops I used a combination of Windows Event Viewer logs and Perfmon, which I analyzed in my View PAL tool. Again, a bunch of findings, with several of interest:
- The VMware View Optimization for Windows 7 script had not run correctly, so some optimizations were not applied.
- AFD Driver adjustment: A simple registry tweak can greatly improve multimedia performance in UDP-based PCoIP View desktops. The registry change is documented here: Low throughput for UDP workloads on Windows virtual machines (2040065)
- Lag when dragging windows between multi-monitor View desktops. Users report lag when dragging Windows’ windows between physical monitors. I detailed the fix for this problem here: Lag When Dragging a Window Between Monitors in VMware View. No downtime is required to fix.
- Low Paged Pool Memory available per View PAL analysis.
- Occasional high kernel times for CPU in perfmon.
- High disk latency and disk queue in perfmon.
The first three findings could correct a few of the reported problems, but not the bulk of the problems – especially the constant disconnects during periods of PCoIP packet loss. The last three findings, however, peaked my interest. Low paged pool memory could be related to poor Windows pagefile performance, and high kernel times could be related to poor disk performance – we may have a storage problem after all! High disk latency and queue length backed this up – let’s focus on storage, again.
Putting the Pieces Together
The storage array and fabric were OK, so the only thing left to investigate on the SAN was the HBAs. I also wanted to have another look at the ESXi hosts. The esxtop and vmkernel.log files provides a good way to get a peek at both, so I enabled SSH on the hosts and grabbed a copy of the logs for analysis and watched esxtop for a bit. Here’s what I found:
- In esxtop, SCSI Command Termination on storage. Above-0 values observed for Command Aborts in the environment. If the Command Aborts value on any vSphere datastore is greater than zero, storage is overloaded on the storage device hosting that datastore. The main causes of overloaded storage are: a.) Placing excessive demand on the storage device, and b.) Misconfigured storage.
- VMFS / File locking. Vkernel.log file on ESXi hosts indicate frequent VMFS file system or VMDK file locking. Error messages in vmkernel.log are similar to the following:
2013-02-03T04:46:37.833Z cpu38:16655)DLX: 3394: vol ‘VDI_HQ_07’: [Req mode 1] Checking liveness of [type 10c00001 offset 180404224 v 272, hb offset 3256320
gen 493, mode 1, owner 510d222f-88581291-1c0e-d4ae527fc5d6 mtime 16758 nHld 0 nOvf 0]
2013-02-03T04:46:41.837Z cpu49:16655)DLX: 3901: vol ‘VDI_HQ_07’: [Req mode: 1] Not free; Lock [type 10c00001 offset 180404224 v 272, hb offset 3256320
gen 493, mode 1, owner 510d222f-88581291-1c0e-d4ae527fc5d6 mtime 16758 nHld 0 nOvf 0] - Frequent (several times per hour or greater) resets of storage path. Entries such as those in the following example indicate HBA Firmware problems:
2013-02-03T04:23:05.988Z cpu52:16101)NMP: nmp_ThrottleLogForDevice:2318: Cmd 0x93 (0x412541519180, 8310) to dev “eui.373333656665362d” on path “vmhba5:C0:T4:L0” Failed: H:0x7 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0. Act:EVAL
2013-02-03T04:23:05.988Z cpu52:16101)WARNING: NMP: nmp_DeviceRequestFastDeviceProbe:237:NMP device “eui.373333656665362d” state in doubt; requested fast path state update…
2013-02-03T04:23:05.988Z cpu52:16101)ScsiDeviceIO: 2324: Cmd(0x412541519180) 0x93, CmdSN 0xde66 from world 8310 to dev “eui.373333656665362d” failed H:0x7 D:0x0 P:0x0 Possible sense data: 0x0 0x0 0x0.
I first checked out VMware’s KB on Interpreting SCSI Sense Codes in ESXi/ESX (289902). The host code of 0x7 could be interpreted as ‘Internal error detected in the host adapter’ per the KB. I then searched the VMware Knowledge Base for possible meanings for this. I found this: When using Emulex HBAs, SCSI commands fail with the status: Storage Initiator Error (1029456).
A quick check and I find that the environment has Emulex HBA’s with seriously outdated firmware. I think I can conclude that the most likely cause of these error messages is an outdated firmware revision on the hosts’ Emulex Fiber Channel Host Bus Adapters (HBA). Other causes may include fiber issues (broken fiber) or FC switch health/configuration, but as the problem can be seen on all hosts, and against both the older EMC array and the new Whiptail array, it is safe to assume that the problem lies upstream from the arrays.
Now I’ve got something really interesting – storage problems on the ESXi hosts. Furthermore, I can observe that at the times when the storage path is reset (timestamps in the logs), VM’s running on connected datastores temporarily freeze. Users perceive this freeze as a Windows hang or as lag. This also explains the poor storage performance and high kernel times in the View desktops. When storage connectivity was lost, VMs couldn’t perform any IO for a bit.
But the big question is, does this HBA issue explain the View disconnects? The answer is yes, and this is how: When storage connectivity was lost via a path reset, IO in the VM stops. When IO in the VM stops the PCoIP Server component of the View Agent on each desktop stops receiving PCoIP packets. The virtual NIC on each desktop was receiving PCoIP packets on the vSwitch port, but the View PCoIP software wasn’t processing those packets. This condition manifests itself as PCoIP Packet Loss when observed through monitoring tools such as VMware vCenter Operations for View or Xangati.
The fix was simple – put the hosts into maintenance mode, shut down the hos,tboot to the Emulex update media, apply the new firmware, and reboot the host. Rinse and repeat. After applying the most recent firmware (check the recommended version from your server, storage, FC switch vendor first), the error messages on the hosts stopped appearing and the disconnects, hangs, and sluggishness on the virtual desktops stopped.
Extend the Fix
Now let’s stairstep (the finalstep in my analytic troubleshooting methodology) the cause a bit. Once the PCoIP Server component started dropping a ton of PCoIP packets, View determined that the desktop was disconnected. An ‘automatically logoff after disconnect’ policy was set on the Linked Clone pools, with a setting of ‘immediately’. Then, a policy of ‘Delete desktop on logoff was set’. When PCoIP packets dropped, View logged off users (causing loss of work), then deleted the desktop, and then re-created new desktops to replace those deleted to meet the minimum number of active desktops for the pool. This happened to all desktops on the host when the storage path was reset. Re-provisioning a few hundred desktops per host takes a while, so users had to wait to get back onto their desktop. Not only were users disconnected, but they lost work, then had to wait (sometimes up to an hour) to get onto a new desktop. Angry users are not fun.
Finally, that lack of redundant storage paths that I eliminated as a problem early on? Yeah, that was a bigger problem than I had originally thought. Had more paths been available, it is possible that a path reset might not have caused a chain reaction in the View pools – it may have been just a little blip of unresponsiveness.
Lessons Learned:
- Design for redundancy, even if you think you’ll not need it.
- The obvious symptom may not immediately explain the problem, so use an analytic troubleshooting methodology to find the root cause. This looked like a PCoIP packet loss problem, with the network as the obvious culprit at the beginning. It ended up being an HBA firmware issue that caused storage connectivity problems!
- Check your vmkernel.log files often. I almost always find something that is a problem or could be improved on when I look at a customer’s log files. This is where the new VMware vCenter Log Insight could come in very handy!
- While all flash arrays are fast and sexy, they don’t solve all your problems. I wish the customer would have called before dropping the cash for a new array as the existing EMC would have been more than enough.
- Engage an expert – a second set of eyes can often uncover issues there you missed. Not only was I able to identify the root cause of the major issues in the environment, but I was able to provide the customer with a ton of other info (a 50 page report) with other improvements, best practices recommendations, etc.
While the exact problem this customer experienced may not hit your environment, I hope my methodology and lessons learned help you if you experience performance issues, disconnects, or other problems in your VMware Horizon View environment.
Questions? Critiques? Leave a comment below!




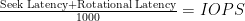
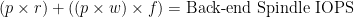
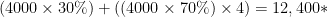
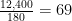
 (LaTeX is the language I used to make the cool math equations – if the forumlas don’t look right drop a comment so I can fix them. WordPress keeps eating the latex syntax…). Hopefully your SAN admin already knows this, so go ahead and give her your front-end IOPS count and read:write ratio and you’ll get some LUN’s presented. But you, the VMware admin, might be responsible for server hardware, including buying the interconnect card (HBA, iSCSI NIC). How do IOPS inform your selection? This is where the alternate formula for calculating IOPS comes in. Here’s the forumla:
(LaTeX is the language I used to make the cool math equations – if the forumlas don’t look right drop a comment so I can fix them. WordPress keeps eating the latex syntax…). Hopefully your SAN admin already knows this, so go ahead and give her your front-end IOPS count and read:write ratio and you’ll get some LUN’s presented. But you, the VMware admin, might be responsible for server hardware, including buying the interconnect card (HBA, iSCSI NIC). How do IOPS inform your selection? This is where the alternate formula for calculating IOPS comes in. Here’s the forumla: